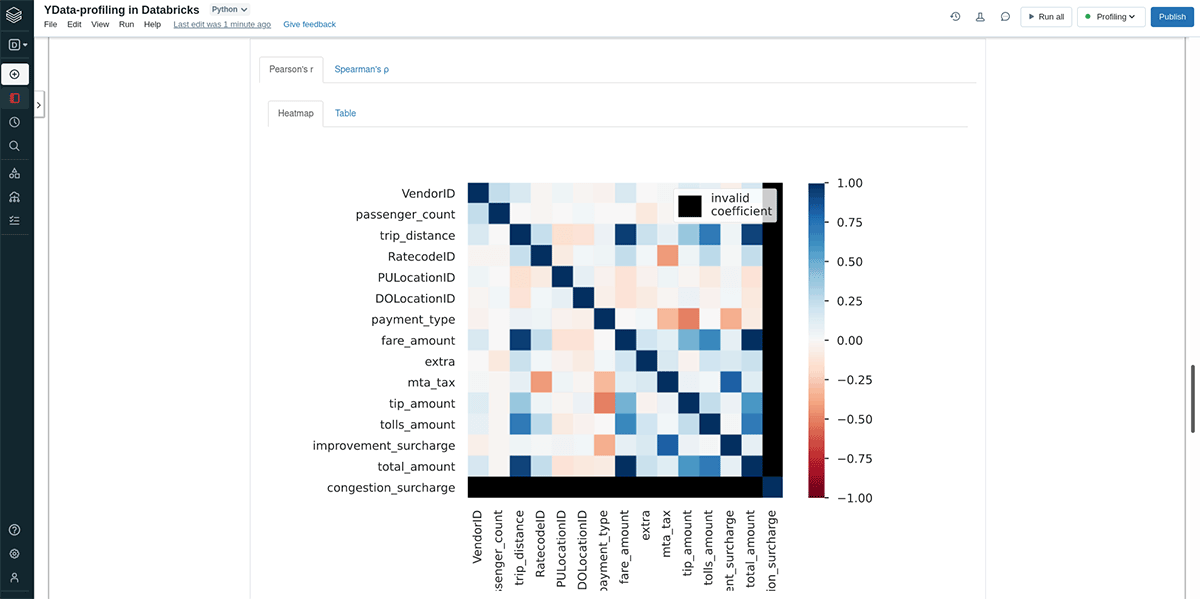
How To Do Data Profiling In Databricks. profiling this dataset in databricks notebooks is as simple as following these easy steps: profiling data in the notebook. this blog aims to highlight a few of the options available to us in azure databricks to profile the data and understand any data cleansing or feature. when you use the display() command in scala or python or run a sql query, the results. data profiling is known to be a core step in the process of building quality data flows that impact business in a. Via the cell output ui and via the dbutils library. Data teams working on a cluster running dbr 9.1 or newer have two ways to generate data profiles in the notebook: this blog aims to highlight a few of the options available to us in azure databricks to profile the data and understand any data cleansing or feature engineering tasks required before we. data profiling can help you make better decisions based on your data, such as how to use it, clean it, or integrate it. learn how to profile pyspark applications using cprofile for performance optimization and identifying bottlenecks in your big data workloads.
from www.databricks.com
data profiling can help you make better decisions based on your data, such as how to use it, clean it, or integrate it. this blog aims to highlight a few of the options available to us in azure databricks to profile the data and understand any data cleansing or feature engineering tasks required before we. data profiling is known to be a core step in the process of building quality data flows that impact business in a. profiling this dataset in databricks notebooks is as simple as following these easy steps: this blog aims to highlight a few of the options available to us in azure databricks to profile the data and understand any data cleansing or feature. Data teams working on a cluster running dbr 9.1 or newer have two ways to generate data profiles in the notebook: learn how to profile pyspark applications using cprofile for performance optimization and identifying bottlenecks in your big data workloads. Via the cell output ui and via the dbutils library. profiling data in the notebook. when you use the display() command in scala or python or run a sql query, the results.
PandasProfiling Now Supports Apache Spark Databricks Blog
How To Do Data Profiling In Databricks learn how to profile pyspark applications using cprofile for performance optimization and identifying bottlenecks in your big data workloads. data profiling is known to be a core step in the process of building quality data flows that impact business in a. profiling data in the notebook. data profiling can help you make better decisions based on your data, such as how to use it, clean it, or integrate it. Data teams working on a cluster running dbr 9.1 or newer have two ways to generate data profiles in the notebook: this blog aims to highlight a few of the options available to us in azure databricks to profile the data and understand any data cleansing or feature. learn how to profile pyspark applications using cprofile for performance optimization and identifying bottlenecks in your big data workloads. Via the cell output ui and via the dbutils library. when you use the display() command in scala or python or run a sql query, the results. this blog aims to highlight a few of the options available to us in azure databricks to profile the data and understand any data cleansing or feature engineering tasks required before we. profiling this dataset in databricks notebooks is as simple as following these easy steps: